

Adding token-level Symbolic vector "feedbacks" to RL architectures...
A Proof-of-Concept sentiment analysis model of a new training/fine-tuning paradigm, aimed at enhancing the reasoning capabilities of LLMs

The AI landscape has been revolutionized by large language models (LLMs) in recent years. These powerful tools have transformed how we approach NLU tasks, pushing the boundaries of what's possible in human-computer interaction. However, despite their impressive capabilities, LLMs have a evident Achilles' heel - their logical reasoning skills.
Imagine an AI that can eloquently discusses Shakespeare but “hallucinates” when asked to solve a complex logic puzzle. This paradox is at the heart of the current LLM problem. Recent AI advancements and work in making LLMs more efficient, have shown that the logical reasoning abilities of contemporary LLMs remain, at best, incomplete and fragmented. That is, they may perform well on certain problem instances but fail significantly on others. While traditional LLMs fine-tuning approaches (via human feedback) do address this problem to some degree, they suffer from many issues like —
"Black-box" reward models : Often, the mechanisms deciding what constitutes a "good" response are opaque and potentially unsound.
Difficulties in collecting preference data : Gathering high-quality preference data from humans is time-consuming and has potential inconsistencies.
Oversimplified feedback : Many current methods rely on sparse, scalar reward values, which fail to capture the nuanced nature of language and reasoning.
These limitations creates a need for methods that can combine the strengths of LLMs with those of symbolic reasoning systems (Knowledge graphs, contraints solver etc.) to create more robust and capable AI systems. The challenge is the integration of these two approaches to leverage their respective strengths while addressing the limitations of current fine-tuning methods like RLHF which are at best expensive, error-prone, and may not fully capture the nuances of reasoning tasks.
Proof-of-Concept
As a proving ground, I thought the best was starting with something simple.
Imagine you're at a party, and someone says, "Well, that movie was... interesting." Without context, it's hard to tell if they loved it, hated it, or felt somewhere in between. This ambiguity is at the heart of why sentiment analysis is such a interesting problem in natural language processing. Traditional approaches to sentiment analysis often rely on binary classifications (positive/negative) or simplistic scalar values. But human sentiment is far more complex. We express emotions with subtlety, sarcasm, and contextual nuances that can be difficult for machines to grasp.
This is where current large language models (LLMs) like GPT-3.5, GPT4 and more, excel - they can capture these nuances to some extent. However, they still struggle with consistent logical reasoning and can produce outputs that, while fluent, may not accurately reflect the intended sentiment or logical structure.
The hypothesis is that by providing more structured, logical feedback during the learning process and by applying Symbolic Reasoning paradigms to the Reinforcement learning system used to fine-tune these models, we can enhance the model's ability to reason about sentiment in a more consistent and nuanced way.
The Research Gap: Beyond Human Feedback
Recent advancements in LLM training have leveraged human feedback through techniques like RLHF (Reinforcement Learning from Human Feedback). While effective, this approach has limitations:
Scalability: Human feedback is time-consuming and expensive to collect at scale.
Consistency: Human judgments can be subjective and inconsistent.
Depth: Humans may not always be able to provide detailed, token-level feedback on model outputs.
These limitations point to a clear research gap —How can we provide more consistent, scalable, and detailed feedback to LLMs during training, particularly for tasks that require logical reasoning and nuanced understanding like sentiment analysis?
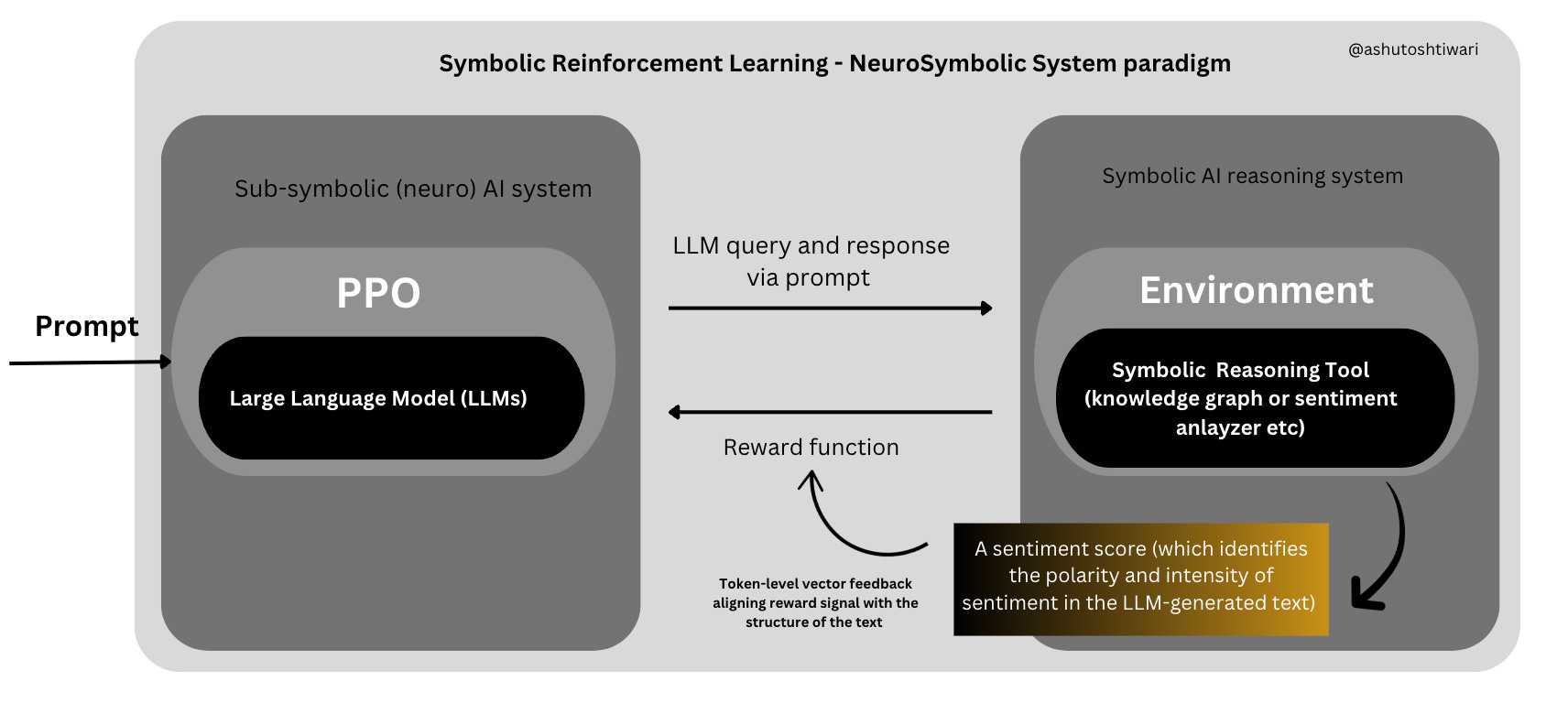
Token-Level Symbolic Feedback with RL
The method used in the project aims to bridge this gap by integrating symbolic reasoning tools into the reinforcement learning process. Here's how it works in the context of sentiment analysis -
The LLM generates a text response to a given prompt.
A symbolic reasoning tool ( Sentiment analysis informed Knowledge graph, sentiment analysis model/LogicNet etc) analyzes the generated text.
The tool provides detailed, token-level feedback on the sentiment expressed in the text.
This feedback is used as a reward signal to fine-tune the LLM.
The key innovation here is the use of a symbolic tool to provide fine-grained, consistent feedback that can capture logical and semantic nuances in the generated text.
Architecture
Let's dive deeper into the technical details of how the project is implemented for sentiment analysis. The core of the system is built around the following components -
Language Model
Utilized a pre-trained autoregressive language model, specifically GPT-2 for imdb reviews, as the foundation. This model, denoted as LM with parameters , defines a probability distribution over sequences of tokens:
\(P(x_{1:T}|\theta) = \prod_{t=1}^T P(x_t|x_{1:t-1}, \theta)\)where
x_{1:T}represents a sequence ofTtokens.Symbolic Environment: This is the sentiment analysis tool. Let’s call it
S.Sis implemented as a rule-based system that operates on tokenized text. It consists of -a) A sentiment lexicon
l: w→[-1, 1], wherewis the set of words and the values represent sentiment polarity and intensity.b) A set of compositional rules
rthat define how sentiment combines at phrase and sentence levels.c) A parse tree generator
tthat structures the input text hierarchically.Reward Function: A function
Rthat converts the output ofSinto a reward signal.The reward function
Rtransforms the output ofSinto a token-level reward signal. It generates a vector of rewards, one for each token in the input sequence-\( R: [0, 1] \times X \rightarrow \mathbb{R}^T\)For a given sentiment score
sand token sequencex_{1:T}, the reward function is defined as:R(s, x_{1:T})_i = {1+sif s>0.5 1−sif s≤0.5 for i = 1, ..., TThis function assigns higher rewards to tokens in positively-sentiment text and lower rewards to tokens in negatively-sentiment text.
Example — if
yis the sentence "The movie started great but ended terribly",Smight return a vector like:\(s = [0.8, 0.8, 0.9, 0.7, 0.3, 0.1, 0.1]\)This captures the shift in sentiment from positive to negative throughout the sentence. The reward function
Rthen processes this vector to provide token-level rewards:\(r = R(s) = [1.8, 1.8, 1.9, 1.7, 0.7, 0.9, 0.9]\)Here, the sentiment scores are trandsformed to rewards, where scores above 0.5 are rewarded (1 + score) and scores below 0.5 are penalized (1 - score).
This fine-grained reward signal allows the LLM to learn not just overall sentiment, but how to construct sentences with appropriate sentiment flow.
PPO Algorithm: Proximal Policy Optimization (PPO) for reinforcement learning is used, but with a critical modification to handle vector rewards. The standard PPO objective is:
\(L^{CLIP}(\theta) = \hat{\mathbb{E}}_t[\min(r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)]\)where
\( r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\)is the probability ratio.
In the modified version, the scalar advantage
\(\hat{A}_t\)is replaced with a vector advantage
\( \hat{A}_t^v\)calculated element-wise from the vector rewards:
\(L^{CLIP}_v(\theta) = \hat{\mathbb{E}}_t[\min(r_t(\theta)\hat{A}_t^v, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t^v)]\)TRL Library Modification:
To implement this vector-based PPO, the Transformers Reinforcement Learning (TRL) library is modified. The key changes include -
Adapting the
PPOTrainerclass to accept vector rewards and compute vector advantages.Modifying the loss computation to handle element-wise operations with vector advantages.
Adjusting the policy and value networks to output vector-valued estimates.
These modifications allow the PPO algorithm to leverage the fine-grained, token-level feedback provided by the reward function.
Training process:
The training process integrates these components as follows -
For input prompt
x, the LM generates a sequence\(x_{1:T} = LM_\theta(p)\).
The symbolic environment analyzes the sequence:
\(s = S(x_{1:T})$\).
The reward function computes token-level rewards -
\(r_{1:T} = R(s, x_{1:T})\)The modified PPO algorithm updates the LM parameters
\(\theta' = \arg\max_\theta \mathbb{E}{x{1:T} \sim LM_\theta(p)}[L^{CLIP}_v(\theta)]\)
This process is repeated iteratively, gradually improving the LM's ability to generate sentiment-appropriate text.
Possible Advantages of using token-level vector feedback
Fine-grained learning - The model receives specific feedback for each generated token allowing for more precise parameter updates.
Contextual understanding - The model can learn how the sentiment of individual tokens contributes to the overall sentiment of the sequence.
Improved exploration - The detailed feedback allows for more informed exploration of the policy space, potentially leading to faster convergence.
By modifying the TRL library to accommodate vector rewards, a framework is created that can provide much more nuanced feedback to language models during the learning process. This approach has the potential to significantly enhance the model's understanding of sentiment expression and, more broadly, to improve learning in tasks that require detailed, contextual understanding.
Results
This is a project in progress, but the initial results are promising. Find it here. These results also seem to suggest that such an architecture allows for more efficient use of model capacity, enabling smaller models to compete with much larger ones on specific tasks.
Work in progress..
While the focus has been on sentiment analysis for now for a proof-of-concept model, the potential applications of this can be vast. Some exciting directions for to pursue here could involve various tasks the current LLMs are great at, like -
Logical Reasoning - Using symbolic logic systems to provide feedback on the logical consistency of LLM outputs.
Code Generation - Leveraging compilers and static analysis tools to provide feedback on generated code.
Mathematical Problem Solving - Using computer algebra systems to guide LLMs in solving complex math problems.
Fact-Checking - Integrating knowledge bases to provide feedback on the factual accuracy of generated text.
Find the Github project code here.